
聊一聊服务治理三板斧:限流、熔断、降级和go-sentinel的实现
2024-01-19 18:37:46
146
林溪
我们知道,对于一个项目之初,我们不可能上来就按几千的并发去配置,为什么?两个方面,第一个是成本高。第二个是维护难度大。即便是天猫淘宝这种,也是采用的动态扩容的方式来应对双十一。那么一个项目如何应对突然的高并发,我们有哪些常用的措施和处理呢?我们接下来就来看看 限流熔断和降级
限流
比如系统本来可以处理1000个请求,忽然一下子来了2000个,为了不让系统崩溃,最简单的方式,就是限流,我只接1000个,超出1000个的不提供服务。 那么限流的方法有哪些呢?我们继续看。
流量计数器
看名字就知道了,比如限制每秒的请求数,比如我们每秒限1000。但是这样有一个问题,就是这种流量计数在某个时间点可能是失效的。因为这种计数的前提是在1s内我们假定了请求是匀速的。但是如果是这种情况,就可能起不到限流的效果。
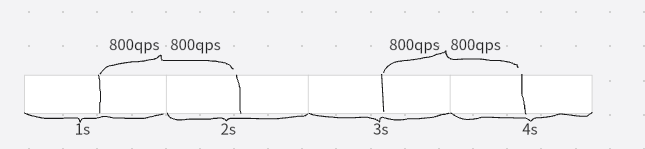
滑动时间窗口
既然以时间为界限不行的话,我们就以时间窗口为界限,保证每个时间段内都不能超过1000qps
漏桶算法
一个请求在被系统处理之前,先找一个漏桶存起来,然后再以固定速率流出,比如这个漏桶可以存1000个请求,如果漏桶中有超出1000个未被处理的请求,那么这部分请求就会溢出,也就是被丢弃,比如我们常用的消息队列。
令牌桶算法
令牌桶就是以固定的速率产生,并缓存到令牌桶中,每个请求必选先获取令牌才能系统处理,令牌桶存满的时候,多余的令牌被丢弃。
nginx的限流
我们以nginx为例,看一下nginx是怎么限流的。 nginx的限流主要有两种方式,一种是限制访问频率,一种是限制并发连接数。
limit_req_zone:用来限制单位时间内的请求数,即速率限制 , 采用的漏桶算法 “leaky bucket”。例如下面的配置
http {
# 定义限流策略 $binary_remote_addr代表限流对象,表示基于客户端ip限流
# zone:定义内存区大小,表示用10m的空间来存储ip
# rate 1r/s表示每秒处理一个请求,nginx实际的管理单位时间是毫秒,其实就是 1000ms处理一个请求
limit_req_zone $binary_remote_addr zone=rateLimit:10m rate=1r/s ;
# 搜索服务的虚拟主机
server {
location / {
# 使用限流策略,burst=5,重点说明一下这个配置,burst 爆发的意思,这个配置的意思是设置一个大小为 5 的缓冲区(队列)当有大量请求(爆发)过来时,
# 超过了访问频次限制的请求可以先放到这个缓冲区内。nodelay,如果设置,超过访问频次而且缓冲区也满了的时候就会直接返回 503,如果没有设置,则所
# 有请求会等待排队。
limit_req zone=rateLimit burst=5 nodelay;
}
}
}
我们1s内发起200个请求看一下,6个请求成功了,也就是每秒1个的请求和5个缓冲区请求成功,其他的返回503
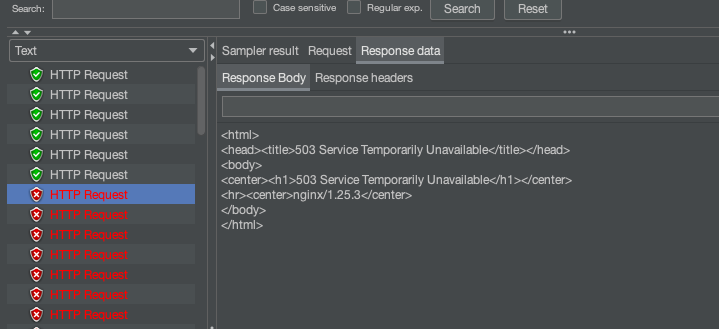
limit_conn_zone:用来限制同一时间连接数,即并发限制。
http {
# 定义限流策略
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
# 搜索服务的虚拟主机
server {
location / {
# 对应的 key 是 $binary_remote_addr,表示限制单个 IP 同时最多能持有 1 个连接。
limit_conn perip 1;
# 对应的 key 是 $server_name,表示虚拟主机(server) 同时能处理并发连接的总数。注意,只有当 request header 被
后端 server 处理后,这个连接才进行计数。
limit_conn perserver 10 ;
proxy_pass http://train-manager-search ;
}
}
}
降级
我们前面看到了,限流之后有一部分的请求直接返回的503,这样对用户体验非常不好,但是我们可能有时候会看到这样的页面,比如
熔断
熔断这个词大家应该是熟悉的,比如家里的保险丝,当电流过大或者发生短路的时候,就会熔断,从而避免发生更大的危害。服务熔断也类似,当被调用方出现故障。调用方出于自我保护的目的,主动停止调用。为什么要主动停止调用?我之前就有过这样的经历,由于某个MySQL服务器性能的问题,执行一个SQL要好几秒。MySQL的请求越来越多,最终导致MySQL宕机,接着php的请求也越来越多,php进程打满,最终php也跟着报错。最终整个服务挂掉。
技术选型
前面我们讲了限流 熔断 和降级 ,并且用nginx演示了限流的示例。我们接下来就来看看go中,有哪些组件可以实现流量控制呢,这里我们挑出来两个常见的sentinel和hystrix来对比一下,基于功能性,我们选择了sentinel。

sentinel
Sentinel 是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。可以看到,sentinel是2020年推出了go版本。

sentinel-golang实现限流
首先,文档地址先找到
流控的配置规则
一条流控规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
Resource:资源名,即规则的作用目标。 TokenCalculateStrategy: 当前流量控制器的Token计算策略。Direct表示直接使用字段 Threshold 作为阈值;WarmUp表示使用预热方式计算Token的阈值。 ControlBehavior: 表示流量控制器的控制策略;Reject表示超过阈值直接拒绝,Throttling表示匀速排队。 Threshold: 表示流控阈值;如果字段 StatIntervalInMs 是1000(也就是1秒),那么Threshold就表示QPS,流量控制器也就会依据资源的QPS来做流控。 RelationStrategy: 调用关系限流策略,CurrentResource表示使用当前规则的resource做流控;AssociatedResource表示使用关联的resource做流控,关联的resource在字段 RefResource 定义; RefResource: 关联的resource; WarmUpPeriodSec: 预热的时间长度,该字段仅仅对 WarmUp 的TokenCalculateStrategy生效; WarmUpColdFactor: 预热的因子,默认是3,该值的设置会影响预热的速度,该字段仅仅对 - WarmUp 的TokenCalculateStrategy生效; MaxQueueingTimeMs: 匀速排队的最大等待时间,该字段仅仅对 Throttling ControlBehavior生效; StatIntervalInMs: 规则对应的流量控制器的独立统计结构的统计周期。如果StatIntervalInMs是1000,也就是统计QPS。
这里特别强调一下 StatIntervalInMs 和 Threshold 这两个字段,这两个字段决定了流量控制器的灵敏度。以 Direct + Reject 的流控策略为例,流量控制器的行为就是在 StatIntervalInMs 周期内,允许的最大请求数量是Threshold。比如如果 StatIntervalInMs 是 10000,Threshold 是10000,那么流量控制器的行为就是控制该资源10s内运行最多10000次访问。
接下来我们参照官方的demo,写一个更简单易懂的一段代码来解释
先来看一下最简洁的丐版
package main
import (
sentinel "github.com/alibaba/sentinel-golang/api"
"github.com/alibaba/sentinel-golang/core/base"
"github.com/alibaba/sentinel-golang/core/flow"
"log"
)
func main() {
//初始化sentinel
err := sentinel.InitDefault()
if err != nil {
log.Fatalf("初始化sentinel失败:%v", err)
}
//配置限流规则 可以根据resource配置多个规则
_, err = flow.LoadRules([]*flow.Rule{
//rule1规则:1000ms内最多处理10个请求,多余的直接拒绝
{
Resource: "rule1", //规则的名称
TokenCalculateStrategy: flow.Direct, //当前流量控制器的Token计算策略。Direct表示直接使用字段 Threshold 作为阈值;WarmUp表示使用预热方式计算Token的阈值。
ControlBehavior: flow.Reject, //表示流量控制器的控制策略;Reject表示超过阈值直接拒绝,Throttling表示匀速排队。
Threshold: 10, //表示流控阈值;如果字段 StatIntervalInMs 是1000(也就是1秒),那么Threshold就表示QPS,流量控制器也就会依据资源的QPS来做流控。
StatIntervalInMs: 1000, //StatIntervalInMs 和 Threshold 这两个字段,这两个字段决定了流量控制器的灵敏度。以 Direct + Reject 的流控策略为例,流量控制器的行为就是在 StatIntervalInMs 周期内,允许的最大请求数量是Threshold。比如如果 StatIntervalInMs 是 10000,Threshold 是10000,那么流量控制器的行为就是控制该资源10s内运行最多10000次访问。
},
})
if err != nil {
log.Fatalf("初始化sentinel加载限流规则失败:%v", err)
}
//最终的限流实现通过这个方法实现
e, b := sentinel.Entry("rule1", sentinel.WithTrafficType(base.Inbound))
if b != nil {
log.Println("限流了")
} else {
log.Println("未限流")
e.Exit()
}
}
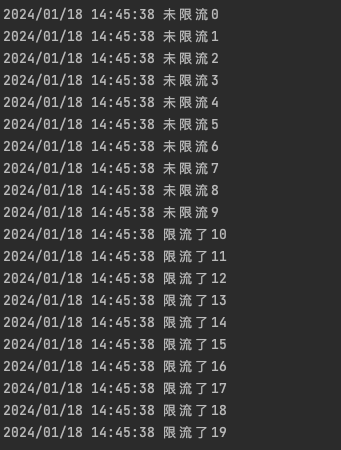
上面我们看到,是通过Entry来计数的,接下来我们通过for循环来,一秒内发送20个计数看看什么样
for i := 0; i < 20; i++ {
//最终的限流实现通过这个方法实现
e, b := sentinel.Entry("rule1", sentinel.WithTrafficType(base.Inbound))
if b != nil {
log.Printf("限流了%d\n", i)
} else {
log.Printf("未限流%d\n", i)
e.Exit()
}
}
我们看到结果,前10个通过,后10个限流了
预热
当前流量控制器的Token计算策略。Direct表示直接使用字段 Threshold 作为阈值;WarmUp表示使用预热方式计算Token的阈值。
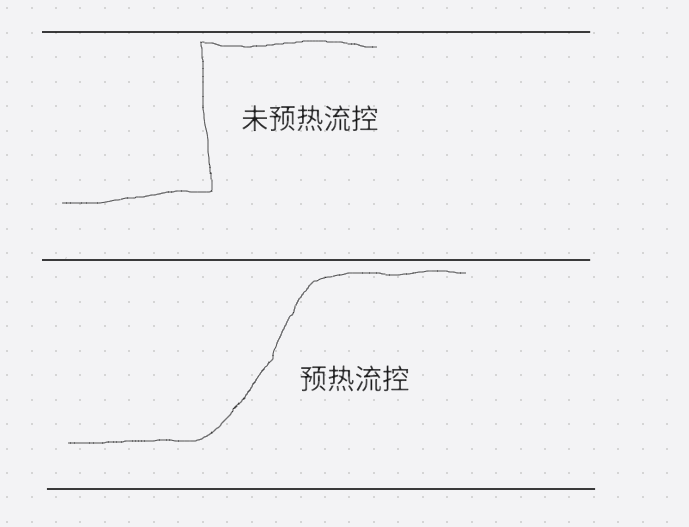
WarmUp Direct我知道了,但是预热是什么意思呢?我们举个例子,比如我们的流量一直是低水位的,限流配置的颗粒度也比较大,5s内控制2000个流量,但是我们前面说过,流量计数的话,你配置了5s内2000个,很可能在100ms内就打进来2000个请求,那系统可能就奔溃了。所以sentinel提供了这种WarmUp 方式,即预热/冷启动方式。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。 相关代码如下
func main() {
//初始化sentinel
err := sentinel.InitDefault()
if err != nil {
log.Fatalf("初始化sentinel失败:%v", err)
}
//配置限流规则 可以根据resource配置多个规则
_, err = flow.LoadRules([]*flow.Rule{
//rule1规则:1000ms内最多处理10个请求,多余的直接拒绝
{
Resource: "rule1", //规则的名称
TokenCalculateStrategy: flow.WarmUp, //冷启动
ControlBehavior: flow.Throttling, //表示流量控制器的控制策略;Reject表示超过阈值直接拒绝,Throttling表示匀速排队。
Threshold: 1000, //表示流控阈值;如果字段 StatIntervalInMs 是1000(
// 也就是1秒),那么Threshold就表示QPS,流量控制器也就会依据资源的QPS来做流控。
//配置预热时长
WarmUpPeriodSec: 20, //30s内达到1000
},
})
if err != nil {
log.Fatalf("初始化sentinel加载限流规则失败:%v", err)
}
ch := make(chan int) //阻塞程序
var globalTotal, passTotal, blockTotal int64
var perGlobalTotal, perPassTotal, perBlockTotal int64
var globalTotalOld, passTotalOld, blockTotalOld int64
//在每一秒统计一次 一秒内通过了多少,总共有多少,block了多少
for i := 0; i < 100; i++ {
go func() {
for {
//10ms执行一次
time.Sleep(1 * 10)
globalTotal++
//最终的限流实现通过这个方法实现
e, b := sentinel.Entry("rule1", sentinel.WithTrafficType(base.Inbound))
if b != nil {
blockTotal++
} else {
passTotal++
e.Exit()
}
}
}()
}
//每秒打印一下统计数
go func() {
nowSec := 1
for {
time.Sleep(1 * time.Second)
perGlobalTotal = globalTotal - globalTotalOld
perPassTotal = passTotal - passTotalOld
perBlockTotal = blockTotal - blockTotalOld
log.Printf("第%d秒接收请求数:%d,通过请求数:%d,block请求数:%d", nowSec, perGlobalTotal, perPassTotal, perBlockTotal)
globalTotalOld = globalTotal
passTotalOld = passTotal
blockTotalOld = blockTotal
nowSec++
}
}()
<-ch
}
20s内逐渐提升至1000
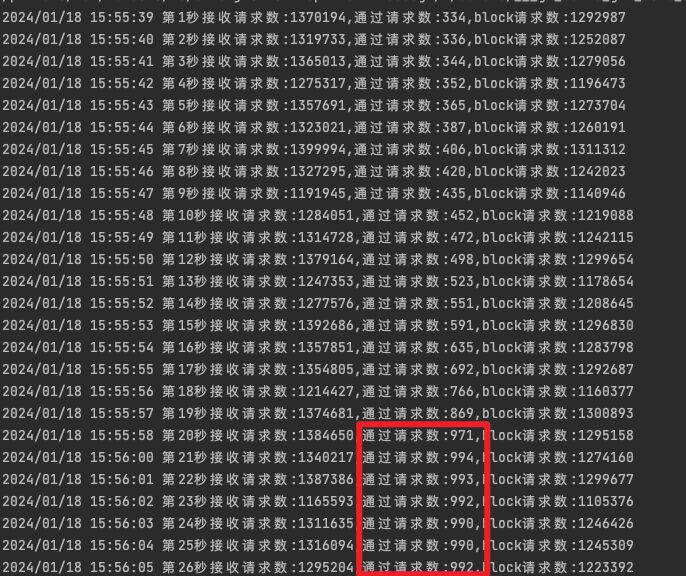
Throttling匀速通过
字段 ControlBehavior 表示表示流量控制器的控制行为,目前 Sentinel 支持两种控制行为:
Reject:表示如果当前统计周期内,统计结构统计的请求数超过了阈值,就直接拒绝。
Throttling:表示匀速排队的统计策略。它的中心思想是,以固定的间隔时间让请求通过。当请求到来的时候,如果当前请求距离上个通过的请求通过的时间间隔不小于预设值,则让当前请求通过;否则,计算当前请求的预期通过时间,如果该请求的预期通过时间小于规则预设的 timeout 时间,则该请求会等待直到预设时间到来通过(排队等待处理);若预期的通过时间超出最大排队时长,则直接拒接这个请求。
匀速排队方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。该方式的作用如下图所示:

这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。 比如我们设置一个1秒内允许通过2个,来试一下,相关代码如下
func main() {
ch := make(chan int)
//初始化sentinel
err := sentinel.InitDefault()
if err != nil {
log.Fatalf("初始化sentinel失败:%v", err)
}
//配置限流规则 可以根据resource配置多个规则
_, err = flow.LoadRules([]*flow.Rule{
//rule1规则:1000ms内最多处理10个请求,多余的直接拒绝
{
Resource: "rule1", //规则的名称
TokenCalculateStrategy: flow.Direct, //当前流量控制器的Token计算策略。Direct表示直接使用字段 Threshold 作为阈值;WarmUp表示使用预热方式计算Token的阈值。
ControlBehavior: flow.Throttling, //表示流量控制器的控制策略;Reject表示超过阈值直接拒绝,Throttling表示匀速排队。
Threshold: 2, //表示流控阈值;如果字段 StatIntervalInMs 是1000(
// 也就是1秒),那么Threshold就表示QPS,流量控制器也就会依据资源的QPS来做流控。
StatIntervalInMs: 1000, //StatIntervalInMs 和 Threshold 这两个字段,这两个字段决定了流量控制器的灵敏度。以 Direct + Reject 的流控策略为例,流量控制器的行为就是在 StatIntervalInMs 周期内,允许的最大请求数量是Threshold。比如如果 StatIntervalInMs 是 10000,Threshold 是10000,那么流量控制器的行为就是控制该资源10s内运行最多10000次访问。
},
})
if err != nil {
log.Fatalf("初始化sentinel加载限流规则失败:%v", err)
}
go func() {
for {
stamp := time.Now().UnixMicro()
//最终的限流实现通过这个方法实现
e, b := sentinel.Entry("rule1", sentinel.WithTrafficType(base.Inbound))
if b != nil {
//log.Printf("限流了%d\n",stamp )
} else {
log.Printf("未限流%d\n", stamp)
e.Exit()
}
}
}()
<-ch
}
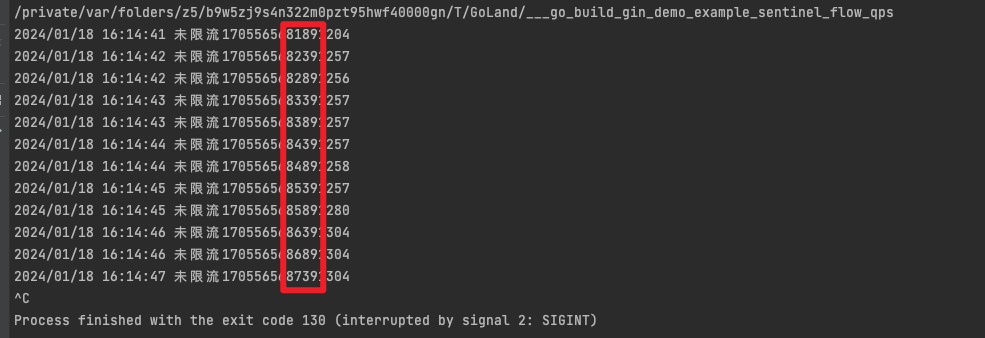
sentinel-golang实现熔断
熔断器模型 Sentinel 熔断降级基于熔断器模式 (circuit breaker pattern) 实现。熔断器内部维护了一个熔断器的状态机,状态机的转换关系如下图所示:

静默期:熔断器的静默期是指在系统检测到异常后的一段时间内,熔断器暂时停止对该异常进行处理或服务的响应。这个时间段是为了让系统有时间自我恢复或避免过度频繁地触发熔断。
静默数:在熔断器的静默期内,系统允许的异常发生次数。当异常发生的次数超过了静默数,熔断器可能会触发并采取相应的措施,例如暂时中止服务以防止进一步的问题。这有助于保护系统免受潜在的破坏性异常的影响。
Sentinel 支持以下几种熔断策略:
慢调用比例策略 (SlowRequestRatio):Sentinel 的熔断器不在静默期,并且慢调用的比例大于设置的阈值,则接下来的熔断周期内对资源的访问会自动地被熔断。该策略下需要设置允许的调用 RT 临界值(即最大的响应时间),对该资源访问的响应时间大于该阈值则统计为慢调用。 错误比例策略 (ErrorRatio):Sentinel 的熔断器不在静默期,并且在统计周期内资源请求访问异常的比例大于设定的阈值,则接下来的熔断周期内对资源的访问会自动地被熔断。 错误计数策略 (ErrorCount):Sentinel 的熔断器不在静默期,并且在统计周期内资源请求访问异常数大于设定的阈值,则接下来的熔断周期内对资源的访问会自动地被熔断。 注意:这里的错误比例熔断和错误计数熔断指的业务返回错误的比例或则计数。也就是说,如果规则指定熔断器策略采用错误比例或则错误计数,那么为了统计错误比例或错误计数,需要调用API: api.TraceError(entry, err) 埋点每个请求的业务异常。
我们先通过简单的丐版代码来看一下
package main
import (
"errors"
"fmt"
"log"
"math/rand"
"time"
sentinel "github.com/alibaba/sentinel-golang/api"
"github.com/alibaba/sentinel-golang/core/circuitbreaker"
)
func main() {
err := sentinel.InitDefault()
if err != nil {
log.Fatalf("初始化sentinel失败:%v", err)
}
ch := make(chan int)
//定制熔断规则
_, err = circuitbreaker.LoadRules([]*circuitbreaker.Rule{
{
Resource: "abc", //熔断器的名字
Strategy: circuitbreaker.ErrorCount, //熔断策略:错误计数策略
RetryTimeoutMs: 3000, //3s内尝试恢复
MinRequestAmount: 10, //静默数
StatIntervalMs: 5000, //5s内统计
StatSlidingWindowBucketCount: 10,
Threshold: 50, //50个错误数
},
})
if err != nil {
log.Fatal(err)
}
var total, pass, block, errnum int64
go func() {
for {
now := time.Now().Second()
total++
e, b := sentinel.Entry("abc")
if b != nil {
block++
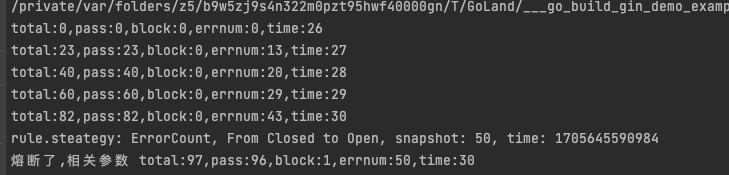
fmt.Printf("熔断了,相关参数 total:%d,pass:%d,block:%d,errnum:%d,time:%d\n", total, pass, block, errnum, now)
time.Sleep(time.Duration(rand.Uint64()%20) * time.Millisecond)
} else {
//假设这里我调用了redis服务,如果返回错误,那么我将trace error
if getRedis() != nil {
errnum++
sentinel.TraceError(e, errors.New("redis error"))
}
pass++
time.Sleep(time.Duration(rand.Uint64()%80+10) * time.Millisecond)
e.Exit()
}
}
}()
go func() {
for {
now := time.Now().Second()
fmt.Printf("total:%d,pass:%d,block:%d,errnum:%d,time:%d\n", total, pass, block, errnum, now)
time.Sleep(time.Second * 1)
}
}()
<-ch
}
// 此方法模拟调用redis
func getRedis() error {
if rand.Uint64()%20 > 9 {
return errors.New("i am error")
}
return nil
}
我们来看一下执行结果,5s内链接失败超过50个,开始熔断


type stateChangeTestListener struct {
}
func (s *stateChangeTestListener) OnTransformToClosed(prev circuitbreaker.State, rule circuitbreaker.Rule) {
fmt.Printf("rule.steategy: %+v, From %s to Closed, time: %d\n", rule.Strategy, prev.String(), util.CurrentTimeMillis())
}
func (s *stateChangeTestListener) OnTransformToOpen(prev circuitbreaker.State, rule circuitbreaker.Rule, snapshot interface{}) {
fmt.Printf("rule.steategy: %+v, From %s to Open, snapshot: %d, time: %d\n", rule.Strategy, prev.String(), snapshot, util.CurrentTimeMillis())
}
func (s *stateChangeTestListener) OnTransformToHalfOpen(prev circuitbreaker.State, rule circuitbreaker.Rule) {
fmt.Printf("rule.steategy: %+v, From %s to Half-Open, time: %d\n", rule.Strategy, prev.String(), util.CurrentTimeMillis())
}
func main(){
//.......
//增加监听
circuitbreaker.RegisterStateChangeListeners(&stateChangeTestListener{})
//.......
}
我们来看一下执行结果,初始状态closed到open
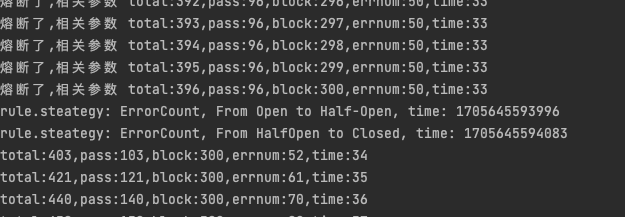
在gin中使用sentinel
我在middleware里面实现限流方法如下
func FlowControl(c *gin.Context) {
//初始化sentinel
err := sentinel.InitDefault()
if err != nil {
log.Fatalf("初始化sentinel失败:%v", err)
}
//配置限流规则 可以根据resource配置多个规则
_, err = flow.LoadRules([]*flow.Rule{
//rule1规则:1000ms内最多处理2个请求,多余的直接拒绝
{
Resource: "rule1", //规则的名称
TokenCalculateStrategy: flow.Direct, //当前流量控制器的Token计算策略。Direct表示直接使用字段 Threshold 作为阈值;WarmUp表示使用预热方式计算Token的阈值。
ControlBehavior: flow.Reject, //表示流量控制器的控制策略;Reject表示超过阈值直接拒绝,Throttling表示匀速排队。
Threshold: 2, //表示流控阈值;如果字段 StatIntervalInMs 是1000(
// 也就是1秒),那么Threshold就表示QPS,流量控制器也就会依据资源的QPS来做流控。
StatIntervalInMs: 1000, //StatIntervalInMs 和 Threshold 这两个字段,这两个字段决定了流量控制器的灵敏度。以 Direct + Reject 的流控策略为例,流量控制器的行为就是在 StatIntervalInMs 周期内,允许的最大请求数量是Threshold。比如如果 StatIntervalInMs 是 10000,Threshold 是10000,那么流量控制器的行为就是控制该资源10s内运行最多10000次访问。
},
})
if err != nil {
log.Fatalf("初始化sentinel加载限流规则失败:%v", err)
}
//最终的限流实现通过这个方法实现
e, b := sentinel.Entry("rule1", sentinel.WithTrafficType(base.Inbound))
if b != nil {
log.Println("被限流了\n")
c.JSON(403, gin.H{"code": 403, "msg": "限流了"})
} else {
log.Println("未限流\n")
c.Next()
e.Exit()
}
}
在路由中指定使用中间件
// 简单组: v1
v1 := router.Group("/v1")
v1.Use(middleware.TraceLog)
v1.Use(middleware.FlowControl)
{
v1.GET("/blog/detail", handlers.BlogDetail)
}
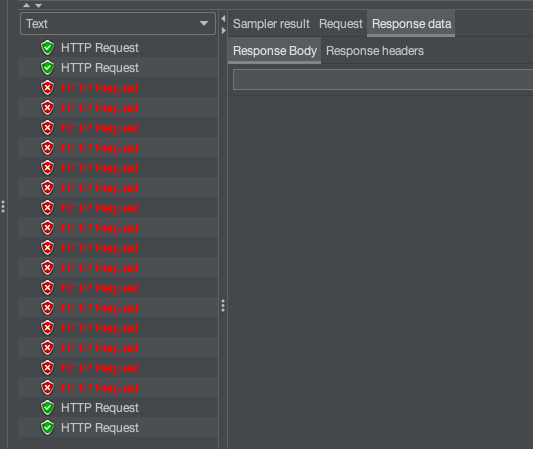
通过jmeter发送20个请求,并查看结果 查看打印日志

相关推荐
phpstorm添加swoole语法提示
1817
2020-05-11

大佬们都说tcp有黏包的问题,tcp却说:我冤枉!
549
2023-03-02
视频直播技术真的很难吗?手把手带你实现直播技术(一)
1714
2021-01-18
同步与异步、阻塞与非阻塞傻傻分不清楚?你得从linux中的5种IO模型看起
768
2022-07-11
快速学习正则表达式,不用死记硬背,这里有份中文资源和互动学习网站
1548
2020-06-11
php安全之道的大略讲解和总结
3887
2020-07-23
不到40行代码教你如何利用php高效快速的爬取10w+网页数据
1530
2020-05-25
明明白白的聊一下什么是服务发现
465
2023-04-11
面试官又双叒叕问你TCP的三次握手和四次挥手?看这里!有图有真相!!
1270
2021-02-23
ChatGPT为什么这么火爆?这是一篇从入门到玩坏的教程
639
2023-02-09
go集成nacos配置中心并读取配置信息
394
2023-05-29
聊一聊进程、线程和协程以及线程的那些“锁“事
1058
2022-02-08
https你很熟?灵魂三连问之https安全在哪里?客户端如何验证https证书的合法性?ssl是如何加密数据的?
268
2023-08-17
让你的工作更高效!快来看看如何使用内网穿透
1193
2021-09-03
php怎么实现类的自动注册
1231
2021-07-23
golang 单元测试和性能测试
1117
2021-12-23
基于docker实现Redis集群(3主3从)
1479
2020-07-15
超详细的RabbitMQ快速入门!!你不拿走吗?
1242
2021-08-04
MySQL的内部XA的二阶段提交
140
2024-01-16

PHP孤儿进程、僵尸进程的代码演示和方法处理
1015
2022-03-01
易查网 资源共享 技术分享 phpstorm 激活码 网盘搜索 IDEA永久激活码_IDEA激活码2022和2023IDEA激活码,IDEA激活码 2022Pycharm激活码,Webstorm激活码 亲测有效 慕课网视频教程 慕课网基础教程
关注公众号 获取验证码
